Every year, PostgreSQL gets faster. Researchers benchmarking the optimizer from version 8 through 16 found an average 15% performance improvement per major release. That’s a decade of consistent, measurable progress. The project has been doing this since 1996.
So when a headline claimed Linux 7.0 just halved PostgreSQL throughput, DBAs, Sys Admins, and DevOps started panicking (in particular, those working with Ubuntu 26.04 LTS which plan to ship Linux kernel 7.0 as soon as possible). It’s worth taking a breath before reaching for the panic button.
The reality is more nuanced. Let me walk you through what actually happened, what it means for your deployment, and what you should genuinely be worried about.
First, a little bit of kernel theory 🔗
Bear with me. I promise this is necessary.
Your operating system kernel is responsible for deciding which program gets to run on the CPU, and when. This is called scheduling. When a program is interrupted mid-execution to let another one run, that’s called preemption.
If you’ve been running PostgreSQL on a server for a while, you know the standard
advice: PostgreSQL should own the machine. It should be the only thing that
matters on that host. We routinely disable the OOM killer so the kernel doesn’t
decide to sacrifice PostgreSQL backends under memory pressure. We tune
vm.swappiness to keep PostgreSQL’s data in RAM. The whole philosophy is: stop
the OS from second-guessing the database.
Preemption mode fits into that same philosophy. Think of it like a surgeon performing a delicate operation. You don’t want someone to tap them on the shoulder mid-incision and say “could you quickly look at something else?”. When PostgreSQL is deep inside a critical section, we really don’t want the kernel to interrupt it either.
Different preemption modes represent different trade-offs.
PREEMPT_NONE (the old server default): the kernel almost never interrupts a running program. The program runs until it voluntarily gives up the CPU, or until it makes a system call. Less context switching, more time doing actual work.

PREEMPT_FULL: the kernel can interrupt any running program at almost any point. Great for responsiveness and real-time applications. Bad for throughput on server workloads.

PREEMPT_LAZY (new in Linux 7.0): a middle ground. The kernel will preempt threads, but lazily, waiting for a natural opportunity rather than forcing an interruption immediately. Designed to reduce the overhead of PREEMPT_FULL while still keeping the kernel’s scheduling model clean.

For the last 20-something years, server kernels shipped with PREEMPT_NONE. PostgreSQL was built with that reality in mind.
Linux 7.0 changes this. Peter Zijlstra’s commit 7dadeaa6e851 removes
PREEMPT_NONE on modern architectures: arm64, x86, powerpc, riscv, s390,
loongarch. All of them. The kernel now only offers PREEMPT_FULL and PREEMPT_LAZY.
Why could this affect PostgreSQL performance? 🔗
PostgreSQL uses spinlocks in several places, notably in its buffer manager.
A spinlock is a lock mechanism where, instead of going to sleep while waiting for a lock to become available, a thread just keeps checking in a tight loop. Think of Donkey in Shrek, strapped in the back seat: “are we there yet? are we there yet? are we there yet?”. This sounds wasteful, but for very short-lived locks, the kind PostgreSQL’s buffer manager uses, it is actually faster than the overhead of putting a thread to sleep and waking it up.
The key assumption behind spinlocks is: the thread holding the lock will release it very soon. Nobody is going to preempt that thread in the middle of a 20ns critical section.
Under PREEMPT_NONE, that assumption held. The lock holder ran until it was done. Other threads spinning and waiting didn’t wait long.
Under PREEMPT_LAZY, the kernel can decide to preempt a thread that’s holding a spinlock. That thread gets put on hold. Every other thread waiting for that lock keeps spinning, burning CPU cycles, until the scheduler decides to resume the original thread. Here is what that looks like across a handful of threads:

In theory, this is a real problem. In practice, what actually happened is more interesting.
What the benchmark actually showed 🔗
Salvatore Dipietro from AWS ran pgbench on a 96-vCPU Graviton4 instance, 1,024 clients, 96 threads, with a 100GB+ shared buffer pool. He got 0.51x throughput compared to Linux 6.x and reported it to the kernel mailing list.
The benchmark script explicitly set huge_pages=off.
That one detail matters enormously. Andres Freund dug into the mailing list thread and found the real culprit: not the spinlock mechanism itself, but TLB misses1 and minor page faults happening while a spinlock was held.
Here is what was actually going on. Without Huge Pages2, PostgreSQL’s shared memory is mapped using standard 4KB pages. On a 100GB+ buffer pool, the first access to each page causes a minor fault. When that minor fault happens while a spinlock is held, the thread stalls. Every other thread waiting for that lock keeps spinning. PREEMPT_LAZY then makes things worse by occasionally scheduling out the stalled lock holder, but the fundamental problem was already the page faults, not the preemption mode.
Andres confirmed this: when he enabled Huge Pages, he could not reproduce the regression. When he disabled them, contention appeared. Salvatore confirmed it too. He re-ran the benchmark, this time enabling Transparent Huge Pages3 on the system, where he found that THP fixed the previous behaviour: throughput came back to around 185k tps on both Linux 6.x and Linux 7.0. Huge Pages and THP work through different mechanisms, but both eliminate the 4KB page fault problem that was causing the contention.
There is a second detail worth noting. The spinlock under contention in the
benchmark, StrategyGetBuffer(), only fires during buffer pool warmup, when
PostgreSQL is still loading pages into shared memory for the first time. Once
the buffer pool reaches steady state and the freelist empties out, that path
is no longer hit. The benchmark was measuring a transient warmup phase and
presenting it as steady-state performance. There is at least one other spinlock
in PostgreSQL that can be contended under the new preemption model, but with a
much lower ceiling on concurrent acquisitions.
Andres put it plainly: a 100GB cold buffer pool, without huge pages, running with 10x more active connections than CPU cores, during warmup only, is not a realistic production scenario.
So should you be scared? 🔗
For a well-configured deployment on bare metal or a dedicated VM: probably not.
If Huge Pages or THP are already enabled on your host, and your workload is not an extreme cold-start scenario with a massive buffer pool, the Linux 7.0 change is unlikely to affect you at steady state. Benchmark with your actual workload and your actual configuration before making any decisions.
The situation is more nuanced in two scenarios.
First: if you are running large shared buffers without Huge Pages or THP on a highly parallel machine. In that case PREEMPT_LAZY can genuinely exacerbate spinlock contention during warmup. The contention exists with PREEMPT_NONE too in that configuration, PREEMPT_LAZY just makes it worse. The fix is to enable Huge Pages or THP, not to pin your kernel.
Second: if you are running PostgreSQL in containers. And this is the concern worth spending time on, because it does not get enough attention.
The real problem: Huge Pages, THP, and containers 🔗
Both Huge Pages and THP mitigate the regression. On bare metal, enabling either is straightforward. In containerized environments, it ranges from painful to impossible, and this is a general PostgreSQL performance concern that long predates Linux 7.0.
THP is controlled by
/sys/kernel/mm/transparent_hugepage/enabled,
a host-level sysfs path. Sysfs is not namespaced in Linux, meaning a container
cannot modify it. Whatever the host has configured is what every container on
that host inherits, with no ability to override it from inside.
Explicit Huge Pages have the same constraint. The host kernel reserves a pool
via vm.nr_hugepages before containers start. A container can consume from
that pool if the host has configured it, but it cannot create or resize it.
Incus, a fully open-source system
container manager, does allow limits.hugepages to cap how many Huge
Pages a given container can consume via the hugetlb cgroup, but the host pool
must exist first.4 A reader running PostgreSQL in Incus reported exactly
this problem: you have to size the pool upfront at the host level. Too small and
PostgreSQL cannot use it. Too large and you have wasted physical RAM that no
other container can touch. The pool is static: changing it means stopping the
container, adjusting the host configuration, and restarting.
In Docker, you need vm.nr_hugepages set on the host before the container
starts, which requires root access to the host. On Docker Desktop the situation
is even worse, as you don’t control the underlying Linux VM at all.
In Kubernetes, nodes must pre-allocate Huge Pages before the kubelet can
advertise them as schedulable resources. You declare hugepages-2Mi or
hugepages-1Gi in your pod spec, but the node has to have the pool ready first.
On managed node pools, EKS, GKE, AKS, you generally cannot control node-level
kernel configuration at all. Changing THP settings from inside a pod requires
either mounting the host /sys as a volume or deploying a privileged DaemonSet,
neither of which most cluster administrators will approve.
This matters beyond the Linux 7.0 story. Running PostgreSQL with a large buffer pool and 4KB pages has always been a performance problem. The Linux 7.0 incident just made it visible in a dramatic way. If your PostgreSQL runs in a container and you cannot control THP or Huge Pages at the host level, you are already leaving performance on the table. The industry has moved heavily toward containerized deployments without fully solving this problem.
The Linux community solution: rseq 🔗
For decades, PREEMPT_NONE acted as a “do not disturb” sign for PostgreSQL, ensuring a thread could finish its work without being interrupted. Linux 7.0 removes this sign. While the new “Lazy” mode tries to be polite, it introduces a level of unpredictability that can turn a 20-nanosecond lock into a millisecond-long bottleneck if the thread is paused at the wrong moment.
Restartable Sequences (rseq) is a Linux kernel mechanism that lets userspace code signal to the kernel that it is inside a critical section, so the kernel delays preemption until after the lock is released:
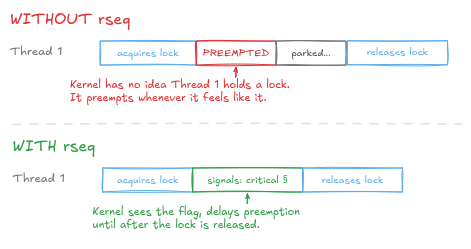
The problem is not the direction of travel. The problem is that removing PREEMPT_NONE and introducing rseq happened in the same release, with no transition period in between. The normal way to retire something is to ship the new way alongside the old, deprecate it, give people time to migrate, then remove it. That step was skipped.
The official solution proposed by the kernel team is to adopt Restartable Sequences (rseq) to mitigate these regressions. However, there is a catch: the necessary slice extension is not enabled by default in Linux 7.0. It requires a kernel compiled with CONFIG_RSEQ_SLICE_EXTENSION and the EXPERT=1 flag. For the vast majority of DBAs and DevOps engineers using standard distributions, this makes the “proper” fix practically inaccessible. As the saying goes, it’s like being told to hold tight to your brush while someone takes away the ladder.5
What should you actually do? 🔗
Before anything else: benchmark with your own workload and your own configuration. A synthetic pgbench result on a 96-vCPU ARM machine with Huge Pages deliberately disabled is not a proxy for your production system.
If you control your host and Huge Pages or THP are already enabled, upgrade to Linux 7.0 and measure. You may see no regression at all.
If neither Huge Pages nor THP are enabled on your host, enable one before
considering a kernel upgrade. For explicit Huge Pages, set vm.nr_hugepages on
the host and huge_pages = try in postgresql.conf. For THP, set
transparent_hugepage=always on the host. Both approaches address the
underlying page fault problem. This is good advice regardless of Linux 7.0.
If you are running PostgreSQL in containers and cannot control THP or Huge Pages at the host level, be aware that this is a general performance concern for large buffer pools. It is worth raising with whoever manages your infrastructure, and worth factoring into your deployment architecture choices.
If you are on Ubuntu 26.04 LTS, which ships with Linux 7.0, do not panic. Test your actual workload. If you see a regression, check your Huge Pages configuration first.
Sources:
-
A TLB (Translation Lookaside Buffer) is a CPU cache that stores recent virtual-to-physical memory address translations. When the CPU needs to access memory, it first checks the TLB. If the translation is not there (a “TLB miss”), it has to walk the page table to find the physical address, which is significantly slower. With 4KB pages and a very large buffer pool, the TLB fills up quickly and misses become frequent. Larger pages reduce the number of entries needed in the TLB and therefore reduce miss rates dramatically. ↩︎
-
Huge Pages (also called HugeTLB pages) are a Linux mechanism for pre-allocating large memory pages, typically 2MB or 1GB, rather than the default 4KB. They must be reserved explicitly before use: the kernel sets aside a pool at boot or via
vm.nr_hugepages, and applications request them explicitly. PostgreSQL supports this viahuge_pages = try|on|offinpostgresql.conf(default istry). Because the pool is pre-allocated and locked in RAM, Huge Pages cannot be swapped out and are not subject to page faults after initial allocation. ↩︎ -
Transparent Huge Pages (THP) is a different mechanism. Rather than requiring explicit pre-allocation, the kernel automatically promotes groups of 4KB pages into larger pages in the background, transparently to the application. No changes to
postgresql.confare needed. The trade-off is less predictability: the kernel’s background promotion and demotion of pages can occasionally cause latency spikes. THP is controlled system-wide via/sys/kernel/mm/transparent_hugepage/enabled, a sysfs path that is global to the host and not part of any Linux namespace. ↩︎ -
Incus exposes
limits.hugepages.[size]to cap container Huge Page usage via the hugetlb cgroup, but this requires the hugetlb cgroup to be available on the host and the host Huge Page pool to be pre-allocated first. See the Incus instance options documentation. ↩︎ -
This comes from a French joke: a madman is repainting his ceiling, and just as he reaches the top of the ladder, his accomplice says “hold tight to your brush, I’m taking the ladder away.” (Un fou repeint son plafond, et au moment où il est au sommet de l’échelle, son complice lui dit “tiens-toi au pinceau, j’enlève l’échelle”.) ↩︎