Thanks to Boris Novikov, who pointed me in the PAX direction in the first place and followed up with many insightful technical discussions. I’m grateful for all his time and the great conversations we’ve had and continue to have.
To dive deeper into the mechanics of PAX, I highly recommend checking out my previous post: PAX: The cache performance you’re looking for.
PAX looks elegant on paper: minipages, cache locality, column-oriented access inside an 8KB page. But the moment you ask how this actually would work with Postgres, the complexity arrives fast. NULL values, variable-length types, MVCC, boundary shifts. Let’s go through it all.
The Minipage Schemas 🔗
In PAX, a page is partitioned into minipages. Here is how they differ depending on the data type. Postgres has an enormous library of types, but they always fall into two storage buckets.
Fixed-Length Attributes (F-minipage) 🔗
This is for types where the size is constant across all rows. Most Postgres types fall into this category: any numeric type, boolean, date/time family, geometric types, network addresses…
Here’s the thing about F-minipages: we don’t store NULL values. At all. No
placeholders. No holes. Just the actual data, packed tight. The bit array?
That’s your map. 1 = “value exists.” 0 = “it’s NULL.”
But wait, if NULL values aren’t stored, how do we know where the bit vector starts?
Let’s step back. The PAX page header contains the total number of records N on the page, and a pointer to the beginning of each minipage (so as many pointers as there are columns). Given the pointer to the start of a minipage and the pointer to the start of the next one, you know exactly how many bytes that minipage occupies.
Now it all falls into place. The bit vector lives at the end of the minipage, and its size is exactly N bits, one per row, NULL or not. Walk back N bits from the end of the minipage, and that’s where your bit vector begins. Everything before it is the dense values array.
Extracting a specific row is pure arithmetic. To get row R:
- check bit R in the bit vector.
- If it’s 0, return NULL.
- If it’s 1, count the number of 1s before position R, call that M.
- The value lives at offset M x S from the start of the values array, where S is the fixed size of the type. That’s it.
No guessing. No delimiters. Just arithmetic a CPU is very good at.
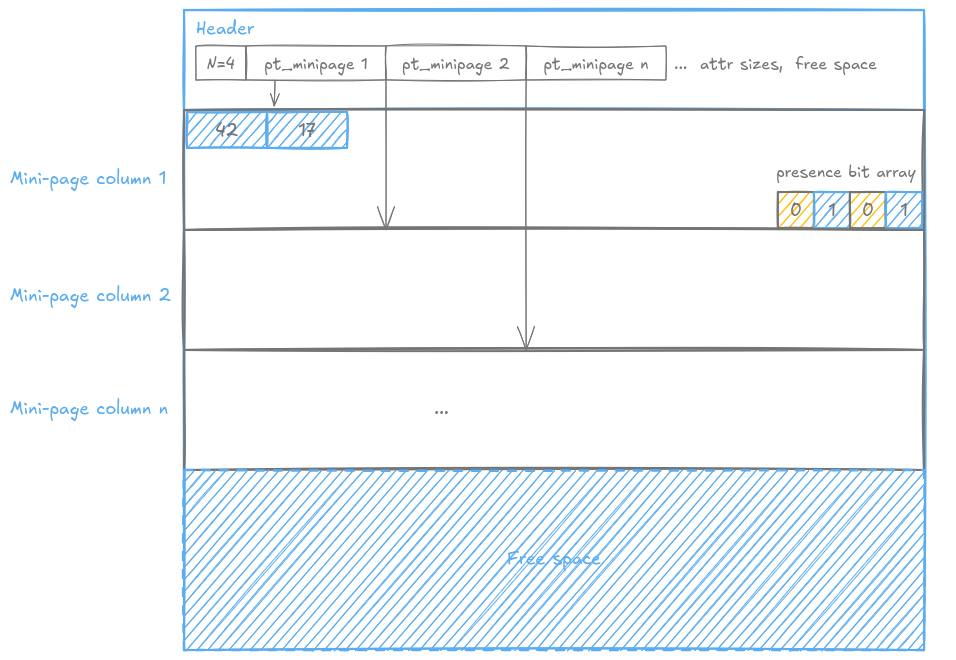
Let’s take the example of row 3 from the above schema:
- Check
bit_array[2]=1→ not NULL - Count the
1s before position 2 →popcount(1, 0)= 1, so M = 1 - The value lives at offset M x S = 1 x 4 = 4 bytes from the start of the values array
- Read the INT4 at that offset →
17
Maximum density. Zero cache waste. The CPU loads pure, packed integers.
And popcount? That’s a hardware instruction. Basically free.
Variable-Length Attributes (V-minipage) 🔗
This category handles types like TEXT or any varying length data type. Values are appended from the front of the minipage, while an array of offsets grows from the back, each offset pointing to the end of the corresponding value. To find where a value starts, you look at where the previous value ends. Simple in theory. Let’s see what happens in practice.
NULLs are handled differently than in F-minipages. No bit array here. A NULL value is denoted by a null pointer in the offset array. The offset array has one fixed-size entry per row regardless, so you always know exactly how many offsets to expect: N, the record count from the page header.
That last point matters. Because offsets are fixed-length (a pointer is just an integer), the offset array at the end of the minipage behaves exactly like the dense array in an F-minipage. Fixed size, predictable, no ambiguity about where it starts: walk back N x sizeof(offset) bytes from the end of the minipage.
Now, what happens when a value is too large? Postgres has a threshold (TOAST_TUPLE_THRESHOLD, 2KB by default) beyond which a value gets TOASTed: stored out-of-line in a separate table. In that case, the V-minipage stores a fixed-length TOAST pointer instead of the raw value. This is actually good news for the layout: a TOAST pointer is fixed-size, so it takes much less space in the minipage than the original value would have, and the offset still points to its end just like any other value. The minipage does not need to know or care whether it’s looking at raw data or a pointer.
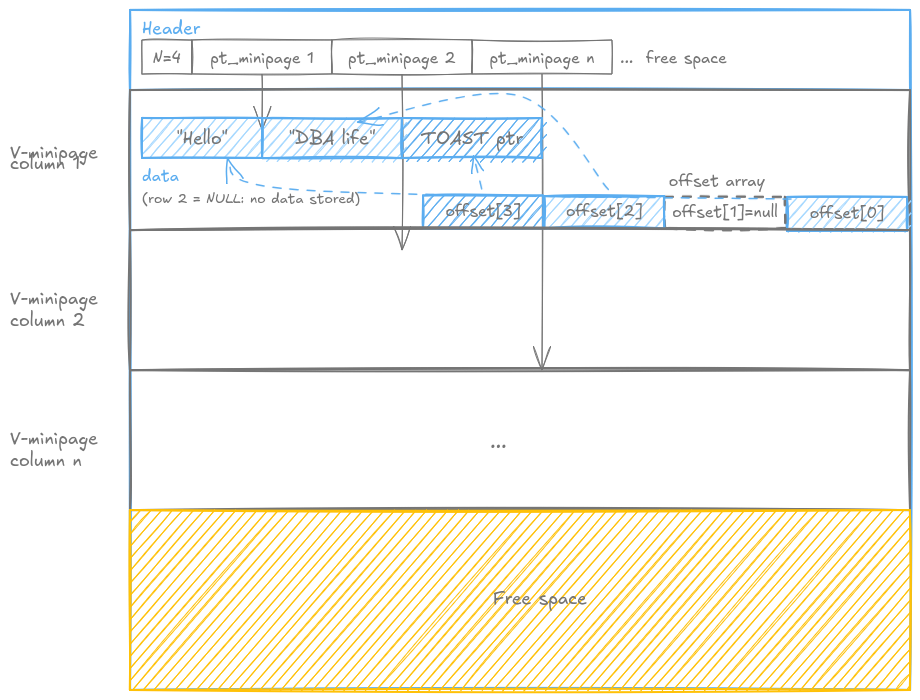
Walk through row 3 (“DBA life”):
- Read
offset_array[2]andoffset_array[1] - Check
offset_array[2]: not a null pointer, so not NULL - Check
offset_array[1]: a null pointer, so checkoffset_array[0], not a null pointer - Read the bytes between
offset_array[0]andoffset_array[2]→"DBA life"
Walk through row 2 (NULL):
- Read
offset_array[1] - Check
offset_array[1]: null pointer → NULL, return nothing - (no need to read the previous offset: a null pointer is conclusive on its own)
Special case — row 1 (“Hello”):
- Read
offset_array[0] - Check
offset_array[0]: not a null pointer, so not NULL - No previous offset: the start of the data zone is known from the minipage structure itself, so offset 0 is implicit
- Read the bytes from the start of the data zone to
offset_array[0]→"Hello"
Insertions, Deletions, Updates 🔗
Insertion 🔗
When a new record arrives, PAX copies each attribute value into its corresponding minipage. For F-minipages, this means appending the new fixed-size value to the dense array and setting the corresponding bit in the presence bit array. For V-minipages, the new value is appended to the front of the data zone and a new offset entry is added to the offset array.
The tricky part is space. If a minipage is full but the page still has global free space, PAX performs a boundary shift: it recalculates minipage sizes based on average value sizes so far, and physically moves minipage contents to redistribute the available space. This is not cheap. It can involve moving significant amounts of data around the page. If the page itself is full, a new page is allocated.
Deletion 🔗
The paper describes deletion as follows: PAX keeps a bitmap at the beginning of the page to track deleted records. Upon deletion, PAX immediately reorganizes the minipage contents to close the gap left by the deleted record, minimising fragmentation and preserving cache density.
This makes sense in the context of Shore, the storage manager the paper was built on. In Postgres, as we will see in the next section, this is where things get complicated.
Update 🔗
PAX updates a fixed-length attribute by computing the offset of the value in its F-minipage and overwriting it in place. For variable-length attributes, if the new value is larger than the old one and the V-minipage has no room, the paper suggests borrowing space from a neighbouring minipage.
We disagree with this approach. Mixing data from different columns inside the same minipage destroys the cache locality that PAX was designed to provide. If your TEXT value overflows into the integer minipage, you are loading irrelevant data into cache alongside your integers. The whole point of PAX is gone.
A better approach: attempt a boundary shift first, redistributing global free space across all minipages. If the page is genuinely full, move the record to a new page. Never borrow from a neighbour.
The MVCC Problem 🔗
All of the above makes sense in the context of the Shore storage manager the paper was built on. In Postgres, things are more complicated.
Postgres never modifies data in place. Ever. This is the foundation of its MVCC implementation. A DELETE does not remove a row. It sets xmax on the old version to mark it as dead. An UPDATE is not an in-place modification. It is a DELETE of the old version followed by an INSERT of the new one. Old versions must remain physically present on the page, readable by concurrent transactions that started before the change.
This is fundamentally incompatible with the paper’s deletion algorithm, which requires immediate minipage compaction to close the gap left by a deleted row. If you compact immediately, you physically destroy data that live transactions might still need to read. You cannot do that in Postgres.
I honestly do not have a clean solution to this problem yet, and I suspect this is one of the reasons PAX has not been implemented in Postgres. If you have ideas, I would genuinely love to hear them.
That said, here is a direction worth exploring.
A Possible Direction: The Metadata Minipage 🔗
What if we added a dedicated metadata minipage, the first minipage on every PAX page, containing all per-row visibility information: xmin, xmax, ctid, and the infomask flags that Postgres already uses to encode visibility information?
Since xmin, xmax, ctid and infomask are all fixed-length integers, this metadata minipage is naturally an F-minipage. No special handling needed. The PAX storage engine treats it like any other fixed-length column.
This also gives us a clean answer to the deletion problem we left open earlier. In Postgres, deletion does not compact anything. It simply sets xmax on the old row version in the metadata minipage, exactly as Postgres does today. The data zones of all other minipages are untouched. Old versions remain physically in place, readable by concurrent transactions that started before the delete.
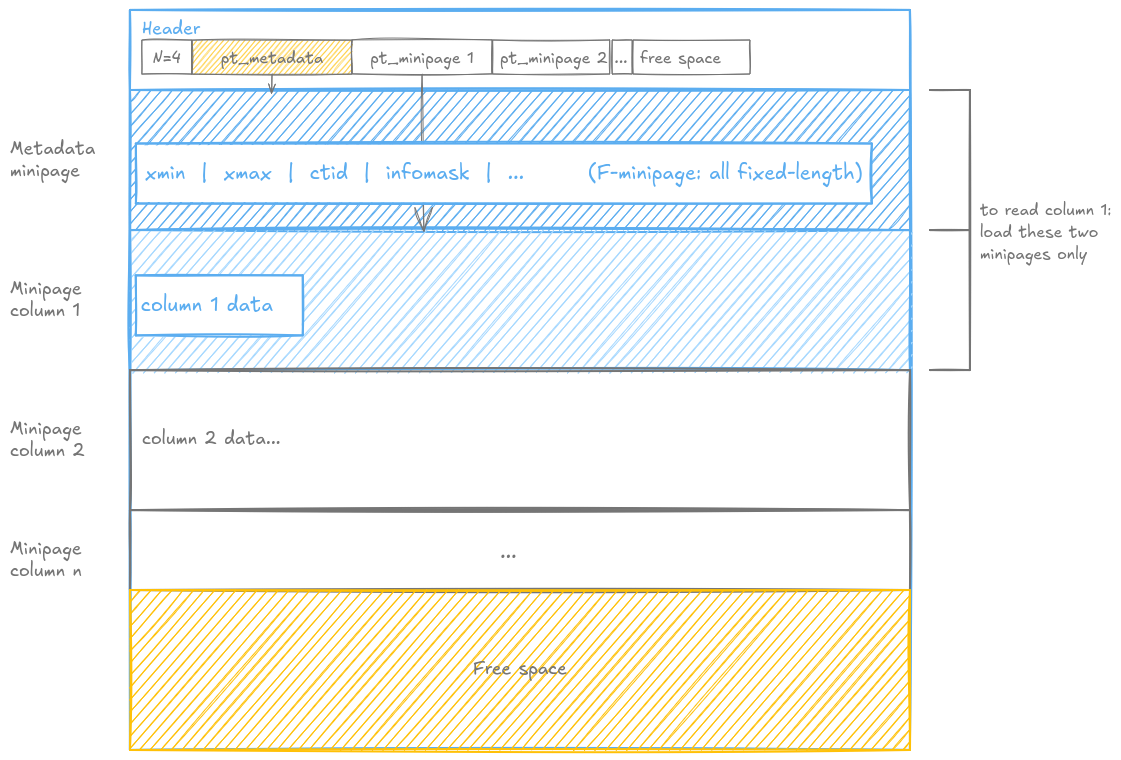
With this design, the three operations become clean. A DELETE simply sets xmax in the metadata minipage. The data zones of all other minipages are untouched, and old versions remain readable by concurrent transactions. An INSERT appends the new row version to each minipage and sets xmin in the metadata minipage. An UPDATE is a DELETE followed by an INSERT, exactly as Postgres does today: the old version stays in place, the new version is appended.
Autovacuum reads the metadata minipage to identify dead versions, those where xmax is older than the oldest active transaction on the cluster, and compacts the data zones safely once no live transaction needs those versions anymore.
To read any value, you always load exactly two minipages: the metadata minipage to check visibility, and the target column minipage to fetch the data. Clean, predictable, cache-friendly.
This is a theoretical design. The engineering details, how exactly the metadata minipage interacts with Postgres WAL, buffer manager, and index machinery, remain open problems. But the direction feels right.
Practical Mitigations: Fillfactor and Toast 🔗
Even setting the MVCC problem aside, boundary shifts are expensive. Two Postgres storage parameters can help significantly.
The first is fillfactor. Postgres already allows you to configure how full a page gets before a new one is allocated. A PAX implementation would benefit from a more conservative default than NSM, around 80%, leaving enough headroom to absorb boundary shifts without triggering full page reorganizations on every insert. It also preserves space for MVCC row versions, keeping UPDATE operations on the same page and allowing HOT updates to work.
The second is toast_tuple_target. Postgres already exposes this parameter to control when variable-length values get compressed or moved to the TOAST table. Lowering it for PAX tables means more values get TOASTed out-of-line, replaced by fixed-size TOAST pointers in the V-minipage. A V-minipage full of fixed-size pointers behaves much more like an F-minipage: predictable sizes, fewer boundary shifts, better cache density. The trade-off is more TOAST table accesses for large values. But in analytical workloads where you are scanning many rows on a few columns, you are often not reading the large variable-length columns anyway.
Together, these two parameters give a PAX implementation meaningful control over the boundary shift problem without requiring changes to the core algorithm:
CREATE TABLE my_table (...)
USING pax
WITH (fillfactor = 80, toast_tuple_target = 512);
Where Does This Leave Us? 🔗
PAX is not a simple drop-in optimization. The paper describes a clean and elegant concept, but mapping it onto Postgres reveals layer after layer of complexity: NULL handling, MVCC compatibility, boundary shift costs, Autovacuum integration, WAL implications.
And yet the core idea remains compelling. The cache pollution problem is real, it is measurable, and it gets worse with every CPU generation. PAX addresses it at exactly the right level: inside the page, without touching the rest of the storage stack.
The metadata minipage direction feels promising. The fillfactor and toast_tuple_target mitigations are practical and available today. The hard engineering work remains to be done, but the path is visible.
This is why I keep writing about it. Not because I have all the answers, but because I think the questions are worth asking out loud.
The journey toward cache-aware storage in Postgres is just beginning. If you are a C developer or a storage enthusiast, I would love to hear your thoughts or collaborate on these concepts. Please contact me directly if you’re interested in discussing how we can bring PAX to life! 🚀
References:
Ailamaki, A., DeWitt, D. J., Hill, M. D., & Skounakis, M. (2001). Weaving Relations for Cache Performance. Proceedings of the 27th International Conference on Very Large Data Bases (VLDB).