I was reading Markus Winand’s latest post on ORDER BY history last week. If you haven’t read it yet, go read it. Markus is one of the best writers on SQL standards, and this post is no exception.
One line stopped me cold. The compatibility table for “expressions on selected columns.” Postgres: partial. PostgreSQL 18: still partial.
That itch needed scratching.
What the standard says 🔗
SQL:1999 lifted a restriction from the original ORDER BY clause. Before 1999, ORDER BY could only reference columns directly produced by SELECT. Since 1999, expressions on those columns should work too.
Concretely, the standard says this should be valid:
select a + b as x
from t
order by coalesce(x, 0);
Markus’s compatibility table shows the split: Oracle, MySQL, MariaDB, DuckDB, Db2, and BigQuery support it fully. PostgreSQL, SQL Server, H2, and SQLite are partial. Six out of ten. Postgres is not the odd one out, but it is on the wrong side of the majority.
Let’s reproduce it 🔗
create table t (
a integer,
b integer
);
insert into t values (1, 2), (3, null), (null, 4), (5, 6);
A bare alias works fine:
select a + b as x
from t
order by x;
x
----
3
11
(4 rows)
Wrap it in an expression and Postgres gives up:
select a + b as x
from t
order by coalesce(x, 0);
ERROR: column "x" does not exist
LINE 3: order by coalesce(x, 0);
^
The workaround is simple enough: repeat the expression.
select a + b as x
from t
order by coalesce(a + b, 0);
Repeating the expression is more typing, but it’s also more explicit. And
that’s good practice anyway. If you use aliases, name them properly.
A single-letter alias like x is a shortcut that saves you three characters
and costs the next reader three minutes. When you do use an alias, give it a
name that means something: total_price, adjusted_score, row_rank.
Better yet, ask yourself whether the alias is necessary at all before adding it.
But it’s still a standard compliance gap. And I wanted to understand why.
This is not a bug 🔗
The documentation is explicit about it. From section 7.5:
Note that an output column name has to stand alone, that is, it cannot be used in an expression. […] This restriction is made to reduce ambiguity.
“To reduce ambiguity.” That’s a deliberate design choice. Let me show you why it’s a harder problem than it looks.
The ambiguity problem 🔗
Consider this table:
create table products (
price numeric,
x numeric -- yes, a column literally named x
);
Now run:
select price * 0.9 as x
from products
order by coalesce(x, 0);
Which x do you mean? The alias x (which is price * 0.9)? Or the
column x from the products table?
The SQL standard has a precedence rule for this: the output column takes
priority. But there’s a catch. If you’re Postgres, and you’ve supported
ORDER BY x meaning “FROM clause column x” forever, you can’t just flip
that switch without breaking existing queries.
In real codebases, the collision won’t look as obvious as this. It’ll be a 12-column table, a query written by someone who left the company twenty years ago, and a silent change in result ordering after an upgrade. That’s the kind of ambiguity that makes database developers lose sleep.
The paper trail 🔗
This isn’t new. Tom Lane raised it on pgsql-hackers in December 1999, before the ink on SQL:1999 was even dry:
“If ‘foo’ is a column name and also an AS-name for something else, ‘GROUP BY foo’ should group on the raw column according to the spec, but right now we will pick the SELECT result value instead.”
The deliberate call was made then: support AS-names in ORDER BY, but only as bare identifiers. Everything else keeps using FROM clause resolution.
Fast-forward to October 2025. Depesz hit the exact same wall on pgsql-bugs:
select unnest(array['d', 'c', 'a']) x order by x <> 'a';
ERROR: column "x" does not exist
Tom Lane’s answer, 26 years later, is unchanged:
“ORDER BY output-column-alias is a messy hangover from SQL92. Supporting both interpretations makes for a lot of ambiguity, so we only allow the old interpretation in exactly the case required by SQL92, namely ‘ORDER BY identifier’.”
Same diagnosis. Same conclusion. The architecture reflects that.
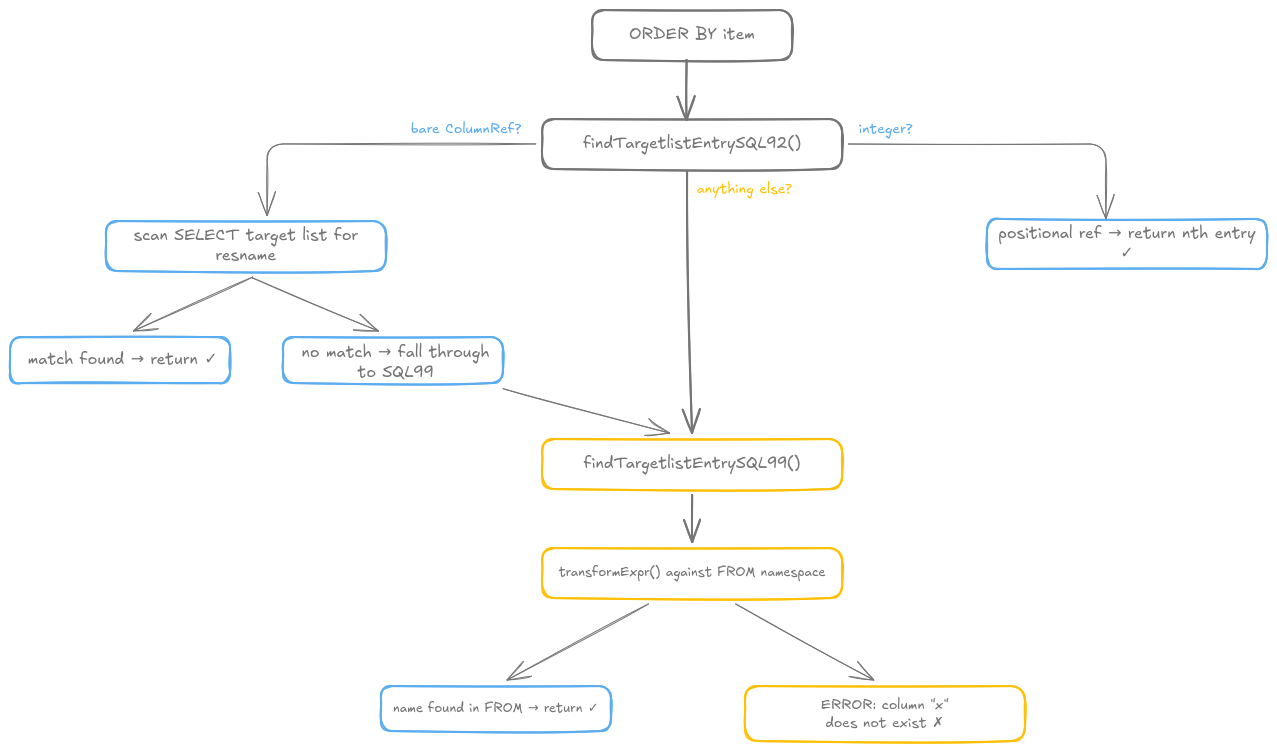
What the parser actually does 🔗
When Postgres parses ORDER BY, it goes through two functions in
src/backend/parser/parse_clause.c.
The first is findTargetlistEntrySQL92.
It handles the special cases: a bare
column name, or a positional integer. For a bare name, it walks the SELECT
target list looking for a matching resname. If it finds one, done. That’s
why ORDER BY x works.
If the ORDER BY item is anything else (a function call, an operator expression,
anything with more than one token), findTargetlistEntrySQL92 punts. It calls
findTargetlistEntrySQL99.
findTargetlistEntrySQL99 does something fundamentally different. It calls
transformExpr(), which resolves names against the FROM clause namespace. At
that point, x is looked up as a column in t. There’s no column x in t.
Error.
Here’s what that flow looks like:
The fix sounds simple: before calling transformExpr(), walk the expression
tree, find any ColumnRef nodes that match a SELECT alias, and substitute the
alias’s expression. Then transform.
It’s not simple. You’d need to handle the precedence question (alias vs. FROM column with the same name) correctly and consistently. You’d need to handle aliases that reference expressions that themselves reference other aliases. You’d need to make sure the substitution happens before type resolution. And you’d need to do all of this without breaking the existing behavior for bare aliases, which people depend on.
Is it worth fixing? 🔗
Honestly? I’m not sure it is.
The ambiguity hasn’t gone away. The SQL standard needed an explicit precedence rule to resolve it, and even that rule creates surprising behavior when a FROM column and a SELECT alias share a name. Implementing the standard correctly here means Postgres would silently change the meaning of some queries that currently error out, and change the meaning of others that currently work.
There’s something to be said for the current behavior: it’s loud. You get an error. You know exactly where the ambiguity is. Fix it by repeating the expression, and the meaning is unambiguous.
There’s a schema-change angle too. Imagine you have a query with an alias, and later someone adds a column to one of the tables with the same name as that alias. With the standard’s precedence rule, the alias wins and nothing changes. Sounds safe. But now rename the alias, and suddenly the new column takes over silently. The sort order changes without a single error. With Postgres’s current behavior, that scenario never happens: the expression errors before it can be misinterpreted.
Going further would make Postgres “plus royaliste que le roi”: more compliant than most users need, at the cost of real implementation complexity and some non-trivial upgrade risks.
The documentation is honest about the limitation. Tom Lane has been consistent about the reasoning for 26 years. And Markus’s table still shows “partial” for Postgres 18.
There’s one more thing worth sitting with. The standard’s precedence rule says the output column wins. A temporary name shadows a column that exists in the actual table. That was a deliberate choice in 1999 to preserve SQL-92 backward compatibility, and it’s internally consistent.
But it doesn’t eliminate the schema-change risk. It moves it. Add a column with the same name as an alias: the alias wins, nothing changes. Now rename the alias: the FROM column silently takes over. Sort order changes. No error, no warning.
Postgres’s error is loud and annoying. It’s also the only behavior that makes that scenario impossible. Is that worth a standard compliance gap? What do you think?
References:
- Markus Winand, SQL’s ORDER BY Has Come a Long Way
- Tom Lane, SELECT … AS … names in WHERE/GROUP BY/HAVING, pgsql-hackers, December 1999
- Tom Lane, Re: order by alias - doesn’t work sometimes?, pgsql-bugs, October 2025
- PostgreSQL documentation, 7.5. Sorting Rows (ORDER BY)
src/backend/parser/parse_clause.c, functionsfindTargetlistEntrySQL92andfindTargetlistEntrySQL99