This was the most common cause of calls at night: your cluster ran out of space. Nowadays, we can add storage on the fly, storage is cheap and (normally) we do monitor disk space so that this should not happen.
Anyhow, how can we deal with such a problem?
To simulate such a problem, I created a virtual host and I created a big empty file to almost fill the file system. Then I simply inserted a lot of rows until the disk ran out of space.
The general diagram 🔗
Here’s how I solve the problem:
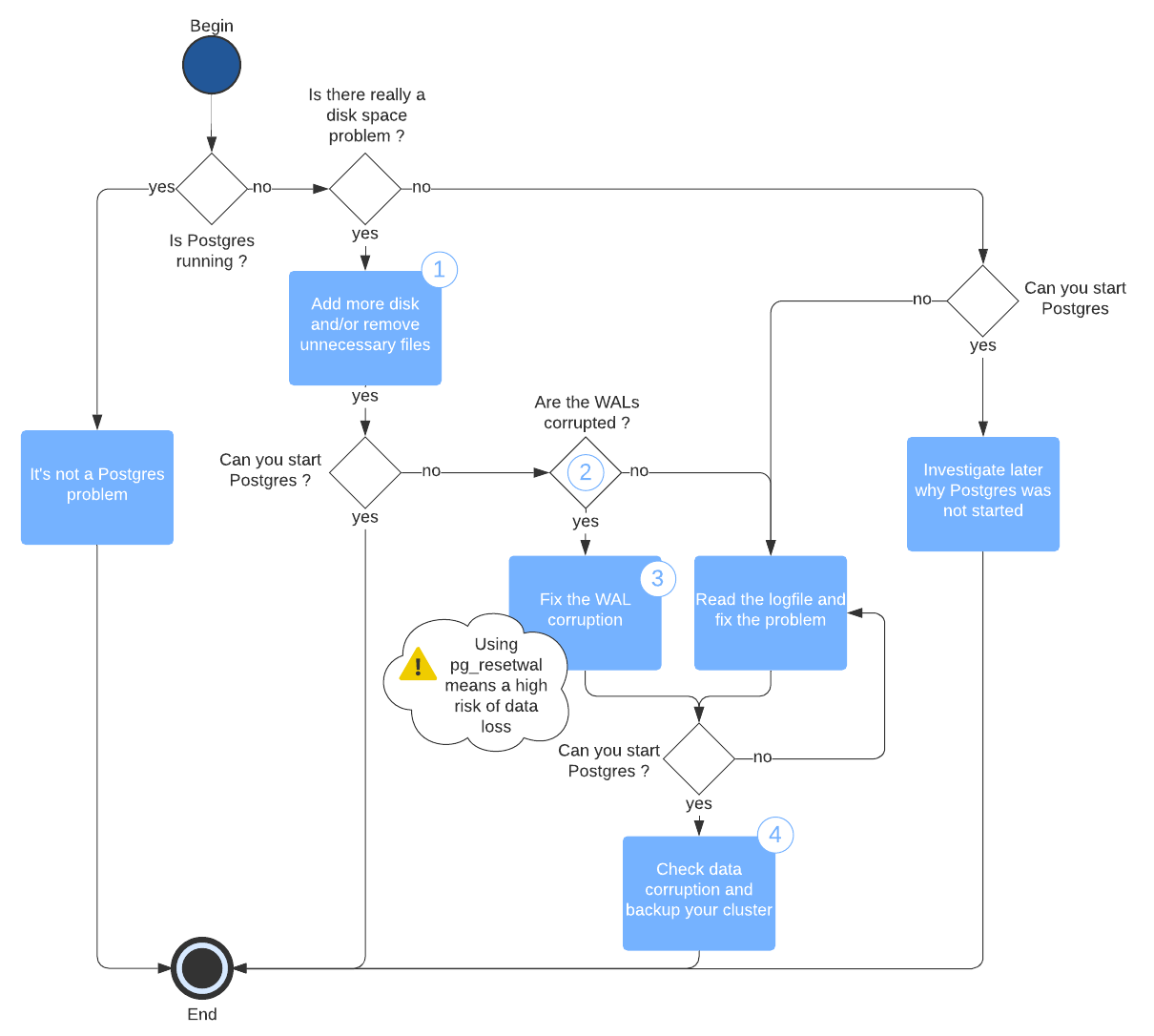
Find some details for some steps here:
1. Add more disk and/or remove unnecessary files 🔗
Whatever you do, never touch anything inside $PGDATA. If $PGDATA contains links
to other directories, don’t touch them too. In particular (and I can’t stress it
enough), never touch a directory named pg_xlog or pg_wal and never touch
a file which name is made of 24 hexadecimal figures.
There is one exception, in case someone had the bad idea to store Postgres log files inside $PGDATA. In that case, you may remove some old log files if there are a lot of them. I strongly encourage you to set your logs properly in the future.
I strongly recommend moving the files you want to delete instead of simply deleting them.
2. Are the WALs corrupted? 🔗
Several log messages should make you think WAL files are corrupted. Here is a list:
- LOG: incorrect resource manager data checksum in record at 0/2000040
- LOG: invalid primary checkpoint record
- PANIC: could not locate a valid checkpoint record
3. Fix the WAL corruption 🔗
The best way to fix a WAL corruption is to restore a copy of the WAL that was streamed either to a standby or to your backup tool (if your backup tool can stream WALs).
But you might not stream your WAL files or they might be corrupted too. In that
case, I strongly encourage you to read the whole documentation
page of the
pg_resetwal tool before trying to use it. Moreover, you should copy the
content of your WAL directory safely to another location before using it.
4. Check data corruption 🔗
Postgres can enable checksums on all data pages. Sadly this mode is not active by default, so the probability that it’s not the case in your cluster is very high.
Anyhow, should you have checksum enabled, use pg_checksums to check for data
corruption (see the
documentation).
If checksums are disabled on your cluster, try using pg_dumpall (or several
pg_dump) to force Postgres to read all your data and check for any corruption.
If you have too much data to store the resulting file (or files), redirect the
output to /dev/null.
Example under Ubuntu 🔗
And that’s how I do it under Ubuntu:
root@elinor:/var/lib# pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
13 main 5432 down postgres /var/lib/postgresql/13/main /var/log/postgresql/postgresql-13-main.log
My Postgres is not running.
root@elinor:/var/lib# df -h
Filesystem Size Used Avail Use% Mounted on
udev 480M 0 480M 0% /dev
tmpfs 99M 11M 89M 11% /run
/dev/sda1 9.7G 9.7G 0 100% /
tmpfs 493M 0 493M 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 493M 0 493M 0% /sys/fs/cgroup
tmpfs 99M 0 99M 0% /run/user/1000
root@elinor:/var/lib# ll -h
total 8.1G
drwxr-xr-x 38 root root 4.0K Mar 8 14:39 ./
drwxr-xr-x 13 root root 4.0K Sep 30 15:52 ../
drwxr-xr-x 4 root root 4.0K Sep 30 15:50 AccountsService/
drwxr-xr-x 2 root root 4.0K Mar 21 13:58 VBoxGuestAdditions/
drwxr-xr-x 5 root root 4.0K Mar 9 03:40 apt/
drwxr-xr-x 8 root root 4.0K Mar 21 13:58 cloud/
drwxr-xr-x 2 root root 4.0K May 5 2018 command-not-found/
drwxr-xr-x 2 root root 4.0K Mar 8 14:06 dbus/
drwxr-xr-x 2 root root 4.0K Apr 16 2018 dhcp/
drwxr-xr-x 2 root root 4.0K Mar 8 14:06 dkms/
drwxr-xr-x 7 root root 4.0K Mar 8 14:30 dpkg/
drwxr-xr-x 2 root root 4.0K Apr 20 2020 git/
drwxr-xr-x 3 root root 4.0K Sep 30 15:51 grub/
drwxr-xr-x 2 root root 4.0K Sep 30 15:51 initramfs-tools/
drwxr-xr-x 2 landscape landscape 4.0K Sep 30 15:51 landscape/
drwxr-xr-x 2 root root 4.0K Mar 9 06:25 logrotate/
drwxr-xr-x 2 root root 0 Mar 21 14:36 lxcfs/
drwxr-xr-x 2 lxd nogroup 4.0K Mar 21 13:58 lxd/
drwxr-xr-x 2 root root 4.0K Sep 30 15:51 man-db/
drwxr-xr-x 2 root root 4.0K Apr 24 2018 misc/
drwxr-xr-x 2 root root 4.0K Mar 9 06:25 mlocate/
drwxr-xr-x 2 root root 4.0K Mar 6 2017 os-prober/
drwxr-xr-x 2 root root 4.0K Sep 30 15:50 pam/
drwxr-xr-x 2 root root 4.0K Apr 4 2019 plymouth/
drwx------ 3 root root 4.0K Sep 30 15:49 polkit-1/
drwxr-xr-x 3 postgres postgres 4.0K Mar 8 14:30 postgresql/
drwxr-xr-x 2 root root 4.0K Sep 30 15:49 python/
drwxr-xr-x 18 root root 4.0K Mar 21 14:04 snapd/
drwxr-xr-x 3 root root 4.0K Sep 30 15:49 sudo/
drwxr-xr-x 6 root root 4.0K Mar 8 14:06 systemd/
-rw-r--r-- 1 root root 8.0G Mar 8 14:39 test
drwxr-xr-x 2 root root 4.0K Mar 8 14:06 ubuntu-release-upgrader/
drwxr-xr-x 3 root root 4.0K Mar 8 14:30 ucf/
drwxr-xr-x 2 root root 4.0K Feb 17 2020 unattended-upgrades/
drwxr-xr-x 2 root root 4.0K Mar 8 14:06 update-manager/
drwxr-xr-x 4 root root 4.0K Mar 21 13:59 update-notifier/
drwxr-xr-x 3 root root 4.0K Sep 30 15:50 ureadahead/
drwxr-xr-x 2 root root 4.0K Sep 30 15:50 usbutils/
drwxr-xr-x 3 root root 4.0K Sep 30 15:49 vim/
The / file system is 100% full. There is a 8GB file named test under
/var/lib.
root@elinor:/var/lib# tail /var/log/postgresql/postgresql-13-main.log
2021-03-08 14:45:08.919 UTC [22579] FATAL: could not write to file "pg_wal/xlogtemp.22579": No space left on device
Just to double-check, the lack of space on the device is the root cause of Postgres being stopped.
root@elinor:/var/lib# rm -f test
root@elinor:/var/lib# du -sh .
243M
I remove the test file.
root@elinor:/var/lib# pg_ctlcluster 13 main start
root@elinor:/var/lib# tail /var/log/postgresql/postgresql-13-main.log
2021-03-21 14:38:49.859 UTC [2414] LOG: starting PostgreSQL 13.2 (Ubuntu 13.2-1.pgdg18.04+1) on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0, 64-bit
2021-03-21 14:38:49.860 UTC [2414] LOG: listening on IPv4 address "127.0.0.1", port 5432
2021-03-21 14:38:49.861 UTC [2414] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
2021-03-21 14:38:49.887 UTC [2420] LOG: database system was shut down at 2021-03-08 14:45:08 UTC
2021-03-21 14:38:49.963 UTC [2414] LOG: database system is ready to accept connections.
Postgres start nicely once it’s able to write again on the device.
Whenever this kind of things happen, just keep your calm and you’ll see you can fix it.