I ran several times into customers with huge writes spikes regularly. Huge means that the system struggles to absorb it and moreover has not finished absorbing it before another one shows up.
It can happen for different reasons, but I found out that most of the time, this was an application issue. I found out anyhow that Postgres can make things worse due to how it is designed.
WAL files, checkpoints and full-page writes
First, you need to know that to prevent any data loss (and because writing into a sequential file is faster than writing directly into the data file), data are written into WAL files before the commit acknowledgment is sent to the application/user. This is a standard way of doing things. Oracle does the same, SQL Server too. Actually I don’t think I know an RDBMS that would do it another way.
From time to time, a checkpoint operation will happen. The RDBMS will take data from the sequential WAL file to copy them into the data files.
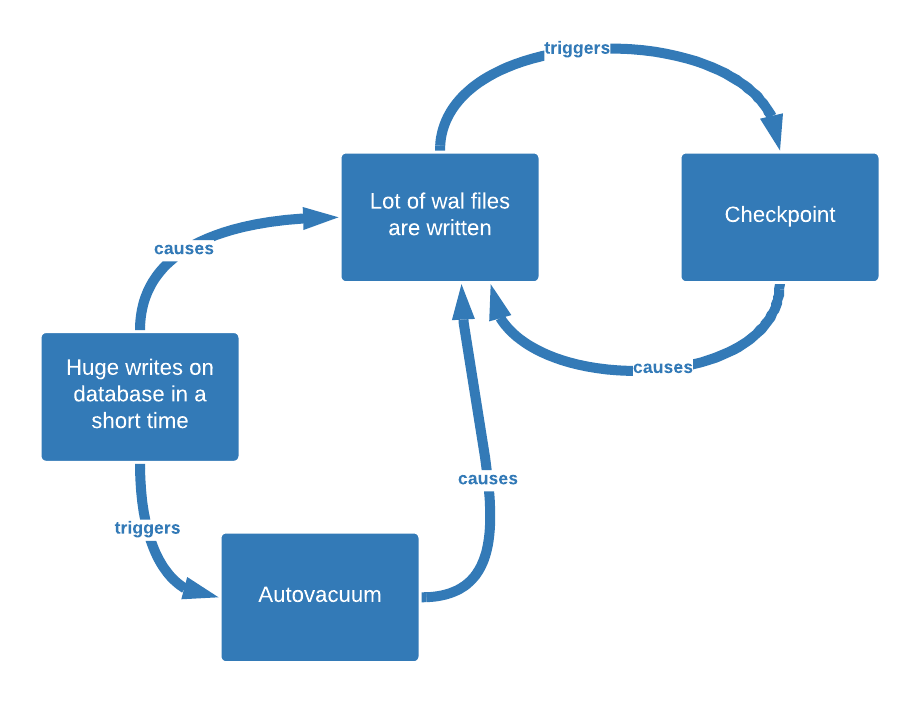
Logically, should you write heavily into your database, you’ll write a lot into WAL files and that will lead to more checkpoints, so more writes into the data files. That shouldn’t make you scratch your head.
This leads us to the next problem: full page writes. You might have encountered
the full_page_writes parameter in Postgres (see Postgres
Documentation
for more information). Unless your data is expandable, don’t disable
full_page_writes.
To prevent data corruption, the first write after a checkpoint operation will write to the WAL full pages instead of only the chunk of data that changed. But in the case of a huge write operation, this can mean several WALs, or even all the WALs between 2 checkpoints.
So, huge writes can lead to more WALs being generated, this will lead to more checkpoints which will lead to more WALs being generated! That’s how we enter a vicious circle.
Enter autovacuum
But it gets worst! In Postgres, MVCC is implemented so that we’ll write new versions of a row each time we need to update a row by logically deleting the old version and writing the new version in the same data file. This is convenient in case a rollback occurs, the old version of the row is always reachable. It also prevents the famous “snapshot too old” you can have for long-running transactions with Oracle.
So, from time to time, we will need to “clean” those rows, logically deleted and not visible to anyone anymore… This is when vacuuming happens. To make maintenance easy, an autovacuum daemon was created (pro tip: never kill an autovacuum process performing for a long time, you’ll have to do it all over again).
This post is not meant to explain autovacuum in detail and there is a lot more to say about it… If you’re interested in that subject please read this Vaccum processing chapter.
Anyhow, as autovacuum makes some writes, it will also create more WAL files. As autovacuum is triggered by the number of rows changed since the last autovacuum, the more rows are changed, the higher the probability it will trigger an autovacuum process will become.
Do you see where that leads? We have another vicious circle entering into town.
Here’s a little graph to explain it:
How to solve that?
I’m sorry to have to answer “it depends.” The best solution would be understand why is the application sending so many writes so often on the database. If the application is doing antipattern like saving application status inside the database, the best way to solve the problem is to fix the application… (Yes, I know, easy to write down, but maybe, next time you won’t fall into that antipattern.) Another solution could be to upgrade your hardware to have faster disks, more memory and more CPU, if your hardware is known to be old and slow.
You can also try to have checkpoints less often by tuning Postgres but remember that you might as well try filling a bathtub with an eyedropper if your huge writes happen for bad reasons (spoiler alert, it’s more than 99% of cases).
To tune checkpoints, you can see that Postgres documentation
page.
I also found out reducing shared_buffers will slow down Postgres and therefore
will reduce the number of WAL files created per minute.